

У сучасному світі, де штучний інтелект охоплює дедалі більше бізнес-процесів, створення надійної безпеки ШІ-інфраструктури компаній стає критично важливим. Згідно з дослідженням IBM, середня вартість витоку даних у 2024 році досягла рекордних $4,88 млн, що на 10% більше, ніж у попередньому році. Захист ШІ-систем від маніпуляцій, шахрайства та витоків даних стають ключовим елементом у побудові систем кібербезпеки, вимагаючи від бізнесів не лише впровадження новітніх технологій, а й формування культури безпеки на всіх рівнях. Як захистити свої ШІ-моделі?
ШІ як чорна скринька
На яких базових алгоритмах ґрунтується робота штучного інтелекту?
Усе, що робить штучний інтелект, – це математика, тобто розвʼязування величезної кількості простих рівнянь. При цьому штучні моделі постійно вчаться. Наприклад, щоб визначити, яке слово поставити у реченні, вони тренуються на великій кількості текстів, роблять розрахунки та запамʼятовують закономірності. Коли ми спілкуємося з такою моделлю, вона аналізує запит і на основі своїх знань видає слова, що здаються їй найбільш слушними. Але ми точно не знаємо, чому вона зробила саме такий вибір, це схоже на «чорну скриньку». Якщо запитати ChatGPT одне й те саме на початку розмови та наприкінці, відповіді можуть бути різними. Це показує, що передбачити, як саме працює ця складна математична модель всередині, важко, а описати її на папері неможливо. Кожна мовна модель ШІ має свою внутрішню будову, де різні частини якось обробляють інформацію і передають її далі, тому чіткого плану, як саме спрацює алгоритм, немає.
Чи є якась умовна межа розвитку ШІ?
Перші технології ШІ зʼявилися в 1990-х – згадати хоча б систему розпізнавання цифр на номерах машин або голосовий помічник Siri на iPhone. Сьогодні ШІ-технології розвиваються настільки швидко, що за кілька років у цій сфері накопичиться достатньо знань, щоб зробити наступний якісний стрибок у розвитку. Принаймні так вважає французький вчений Ян Лекун, один з головних розробників сучасних нейромереж. Але, на мою думку, розвиток штучного інтелекту вже сьогодні стикається з кількома ключовими обмеженнями, які можуть впливати на його подальший прогрес, серед яких – обмежена доступність даних, їхня упередженість і якість, а також проблеми з узагальненням, адже моделі ШІ, навчені на конкретних наборах даних, можуть не працювати належним чином на нових або непередбачуваних даних. Крім того, використання технологій ШІ викликає етичні та соціальні питання, повʼязані з конфіденційністю, безпекою та справедливістю.
Яких змін слід очікувати?
Перш за все збільшиться популярність промпт-інженерів, які будуть інтегровані у віртуальні асистенти, такі як Siri й Alexa, та розумні пристрої. Вони допомагатимуть у створенні правильних запитів або інструкцій, щоб отримувати релевантні відповіді від мовних моделей. ШІ генеруватиме багато контенту, автоматизує роботу та поліпшить спілкування з людьми.
Бізнеси з більш зрілими ШІ-стратегіями перейдуть до повної автоматизації бізнес-процесів, таких як логістика, підтримка клієнтів і маркетинг.
Водночас зростатиме й усвідомлення важливості етичного використання ШІ. Щоб він був безпечним і не порушував авторські права, держави почнуть більше контролювати цю сферу. І, нарешті, ще одна важлива річ – ШІ навчиться розуміти емоції людей, оскільки зростатиме кількість систем, здатних розпізнавати та реагувати на емоції користувачів.
Захист ШІ-систем
У чому головний ризик використання сторонніх ШІ-моделей?
Вся інформація, яку ми вводимо в ChatGPT та подібні сервіси, зберігатиметься там вічність, отже, завжди є ризик, що хтось сторонній добереться до неї. У програмуванні ризики ще вищі. Якщо ми не використовуємо локальні сховища, то передаємо код моделі. Вона його вивчає, зберігає у своїй памʼяті, але у будь-який момент ці дані можуть стати доступними для всіх. Особливо це небезпечно, коли йдеться про якусь важливу чи секретну інформацію, не кажучи вже про безпеку самого сервісу. А що як його зламають хакери, з даними щось станеться? Тому щоб користуватися такими сервісами більш-менш безпечно, потрібно хоча б почитати про їхню політику конфіденційності, подивитися, чи використовують вони якісь сучасні методи шифрування. А ще краще – варто, щоб дані компанії зберігалися на власних компʼютерах і серверах, а не десь за кордоном.
ШІ-моделі компанії мають бути локалізованими.
Чи є якась інструкція, план дій для компаній?
По-перше, варто чітко прописати правила, як користуватися ШІ, щоб усі розуміли, що можна, а що ні. По-друге, думати про ризики наперед і намагатися їх зменшити. По-третє, берегти дані як зіницю ока – обмежувати доступ і шифрувати все, що тільки можна. Ще одна важлива річ: безпеку необхідно вбудовувати в ШІ з самого початку. Це означає використовувати складні паролі, шифрувати дані та слідкувати, щоб ніхто зайвий до них не дістався. В UCloud ми надаємо безліч послуг, повʼязаних із ШІ-безпекою та захистом даних: робимо резервні копії, відновлюємо роботу після якихось проблем, даємо в оренду потужності з гарним захистом, консультуємо і допомагаємо зашифрувати дані.

Дмитро Прокопʼєв, інженер з машинного навчання та штучного інтелекту UCLOUD. Фото Артем Галкин
Для складних обчислень зі штучним інтелектом потрібні потужні GPU. Від чого залежить їх вибір?
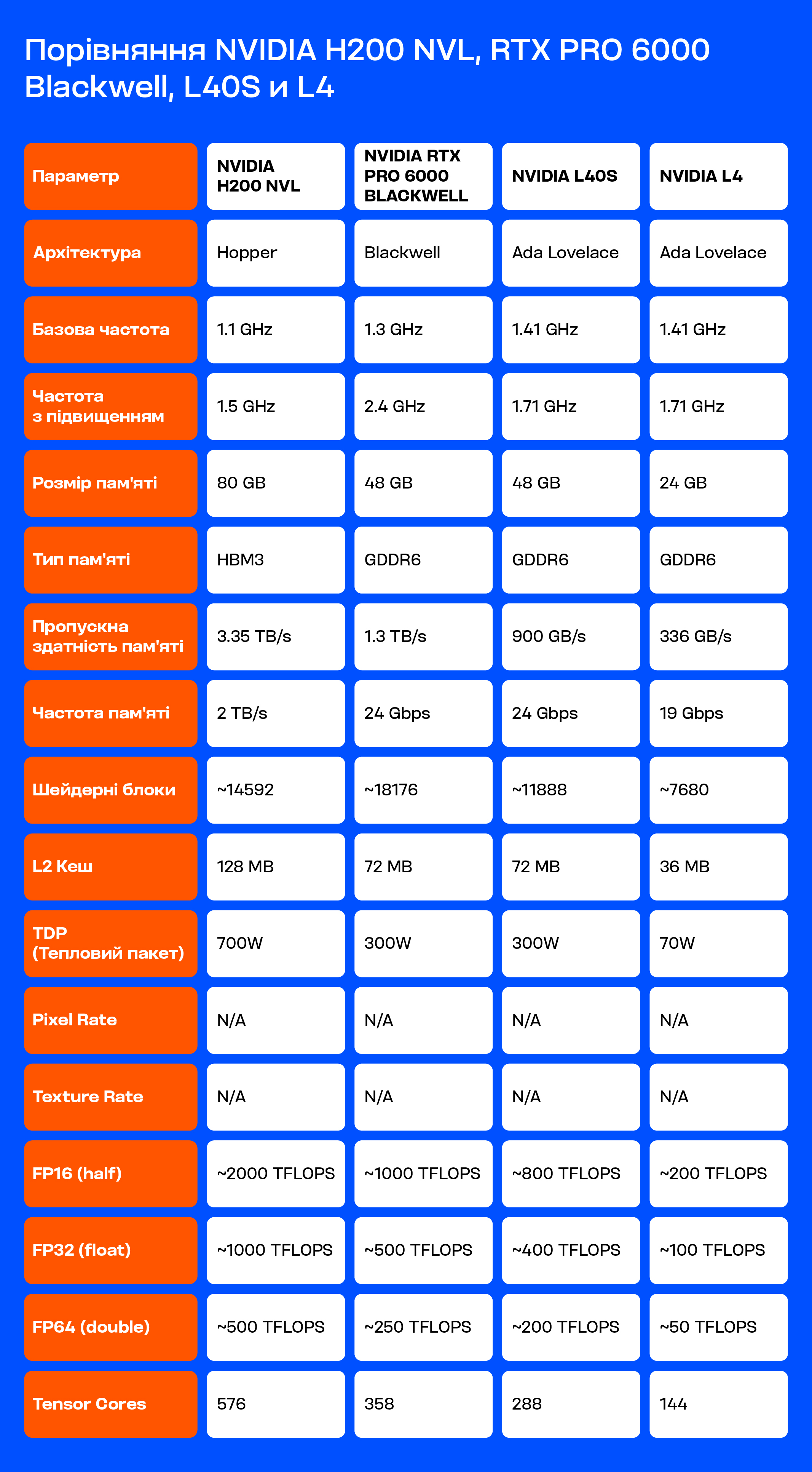
Перш за все це GPU, які швидко обробляють великі обсяги інформації та складні розрахунки. Наприклад, моделі NVIDIA H200 NVL та LS40S добре впораються з такими завданнями, швидко виконуючи різні математичні операції. Щоб GPU працювали ще швидше, в них є спеціальні ядра – Tensor Cores, які прискорюють навчання глибоких нейронних мереж. Але для цього потрібно використовувати спеціальний режим обчислень – змішану точність. Такі потужні GPU сильно гріються, тому їм потрібне хороше охолодження, щоб не перегріватися і не сповільнювати роботу. NVIDIA навіть розробила спеціальні технології, наприклад TensorRT-LLM та NVLink, щоб ШІ працював ефективніше. NVLink допомагає GPU швидко обмінюватися інформацією між собою.
Який саме GPU обрати – залежить від того, наскільки складна модель ШІ, з якою ви працюєте. Наприклад, якщо ви налаштовуєте великі мовні моделі, такі як LLaMA або DeepSeek, то використання NVIDIA H200 NVL з Tensor Cores та NVLink може значно підвищити швидкість обчислень. NVLink допомагає GPU працювати разом як одна команда, що робить обробку даних швидшою.
Чи на часі поява в організаційній структурі компаній посади директора зі штучного інтелекту?
Призначення такого фахівця стає стратегічно виправданим кроком за умов, коли компанія має достатній бюджет, складну інфраструктуру та високий рівень захисту даних. В українських компаніях, таких як «Нова пошта», Prostor та агрохолдинг МХП, вже активно шукають директорів зі штучного інтелекту. Це нова посада, яка поступово з’являється через зростаючий інтерес до штучного інтелекту. Впровадження таких посад є відповіддю на бум штучного інтелекту, подібно до того, як у 2000-х роках бізнес масово впроваджував CRM-системи.
Вы нашли ошибку или неточность?
Оставьте отзыв для редакции. Мы учтем ваши замечания как можно скорее.
