


Многие украинцы полюбили использовать чат-боты, такие как ChatGPT от OpenAI, в качестве помощников по работе. Но для некоторых до сих пор вопрос: почему, если «общаешься» с чат-ботом на английском, он – довольно приличный помощник. Как только пишешь запрос на украинском, можешь получить набор вымышленных фактов. Богдан Питайчук, chief AI officer в Gathers и исследователь ИИ, объясняет, почему чат-ботам так сложно ладить с украинским языком, и когда они смогут на нем свободно «разговаривать» с пользователями.
Купуйте річну передплату на шість журналів Forbes Ukraine за 1259 грн замість 1799 грн. Якщо ви цінуєте якість, глибину та силу реального досвіду, ця передплата саме для вас. В період акції Christmas sale діє знижка 30% 🎁
Английский язык называют наиболее популярным языком программирования. Такие тезисы стали актуальны благодаря ChatGPT и другим подобным инструментам на основе генеративного искусственного интеллекта (AI), поскольку все они гораздо лучше работают именно с английским языком, чем с любым другим.
ChatGPT показывает, что сила генеративного AI доступна буквально каждому человеку, у которого есть интернет. Нейросети помогают писать, продумывать маркетинговые стратегии, обслуживать клиентов и в целом под управлением профессионала становятся важными инструментами, качественно улучшающими и ускоряющими работу.

Однако если вы пробовали пользоваться ChatGPT на украинском, то наверняка получили неудовлетворительный результат и уже успели разочароваться.
Чат-бот понимает вас, даже может выдать относительно неплохой ответ, однако стабильно на высоком уровне на украинском он работать не будет. О качественной помощи в решении рабочих задач вообще речь не идет.
Учитывая то, что технология постоянно развивается и вскоре полностью изменит рынок труда, важно понимать, как она работает.
Почему ChatGPT или другие генеративные AI-инструменты отлично работают на английском и намного хуже на украинском или других языках? И изменится ли это в будущем? Спойлер: да, даже объясню почему.
Токены – ключ к восприятию мира нейросетями
Простейшее объяснение плохого качества текстов на украинском языке – малое количество украиноязычных данных, на которых учился ChatGPT. Частично это правда, однако на самом деле это не главная проблема нейросетей, ведь эти данные на самом деле генерируются.
Как это работает? К примеру, во время тренировки AI анализирует огромное количество текстов на английском о котах и собаках. После этого ему дают похожие тексты на украинском, и в конце концов нейросеть понимает, что cat – это кот, а dog – это собака.
Сейчас искусственный интеллект идет еще дальше. Недавно один из AI-инструментов Google, который в компании тренировали на многих языках, научился понимать и отвечать на языке, которого не было в его базе. То есть модель уловила что-то (исследователи до сих пор не знают, как это произошло), что характерно для всех языков, и это позволило ей расширить свою базу без дополнительных данных.
Поэтому проблема отсутствия большого количества украиноязычных данных, конечно, играет свою роль, но не является корнем проблемы.
Первое, что необходимо знать о нейросетях, – они не воспринимают мир как люди. У них нет глаз, ушей, носа или кожи – AI все «видит» через числа.
Если упростить, интеллектуальность AI проявляется в поиске зависимости между последовательностями чисел. Текст, который мы пишем в диалоговом окне чат-бота, он видит как числа, или, как их называют в профессиональной среде, токены.
Токен – это не просто числовые заменители слов или букв. Это основополагающие блоки, на основе которых модель изучает, понимает и обрабатывает язык. Именно здесь возникает самая важная разница: ChatGPT натренировали на токенах, заточенных под английский язык.
Поэтому английские слова «токенизируются» по примерной формуле «один токен = одно слово». В то же время те же слова или предложения, написанные на украинском языке, используют гораздо больше токенов.
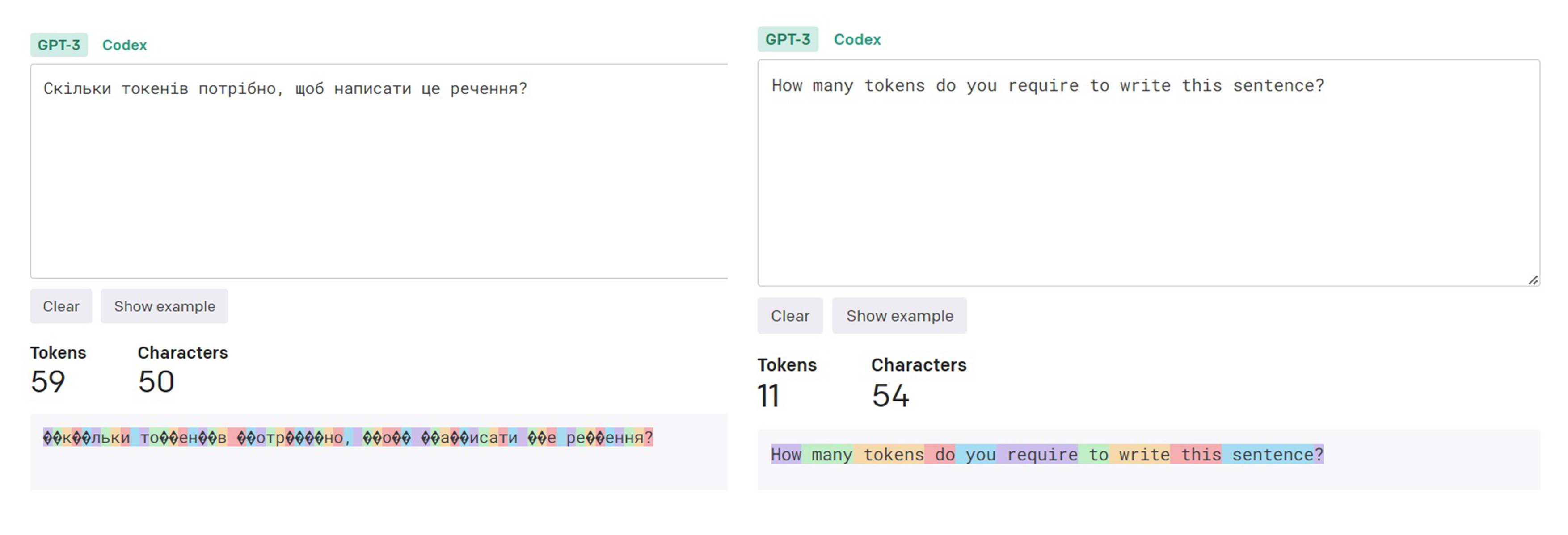
Английские слова «токенизируются» по примерной формуле «один токен = одно слово». В то же время те же слова или предложения, написанные на украинском языке, используют гораздо больше токенов.
Предложение на английском языке состоит из 10 слов, 54 знаков и 11 токенов. На украинском – семь слов, 50 знаков и 59 токенов.
Общаясь с чат-ботом на любом языке, кроме английского, мы будем использовать больше токенов. Языки, в основе которых лежит латиница (например, итальянский или французский), будут тратить примерно в два раза больше токенов. Кириллица же для современных нейросетей пока слишком тяжела, поэтому часто можно увидеть, что даже одна буква «съедает» несколько токенов.
Учитывая ограниченное контекстное окно ChatGPT (каждый диалог – это 8000 токенов), чат-бот тратит гораздо больше памяти только на обработку запроса, не говоря уже о генерации и выдаче результата. Поэтому он быстро «забывает» основную тему и начинает галлюцинировать, то есть придумывать информацию, чтобы написать хоть что-то.
Например, если вы попросите ChatGPT написать стих на английском, то получите в целом неплохой результат – с хорошими рифмами и креативными эпитетами. Если же захотите получить стихотворение на украинском, творение искусственного интеллекта вряд ли вам понравится.
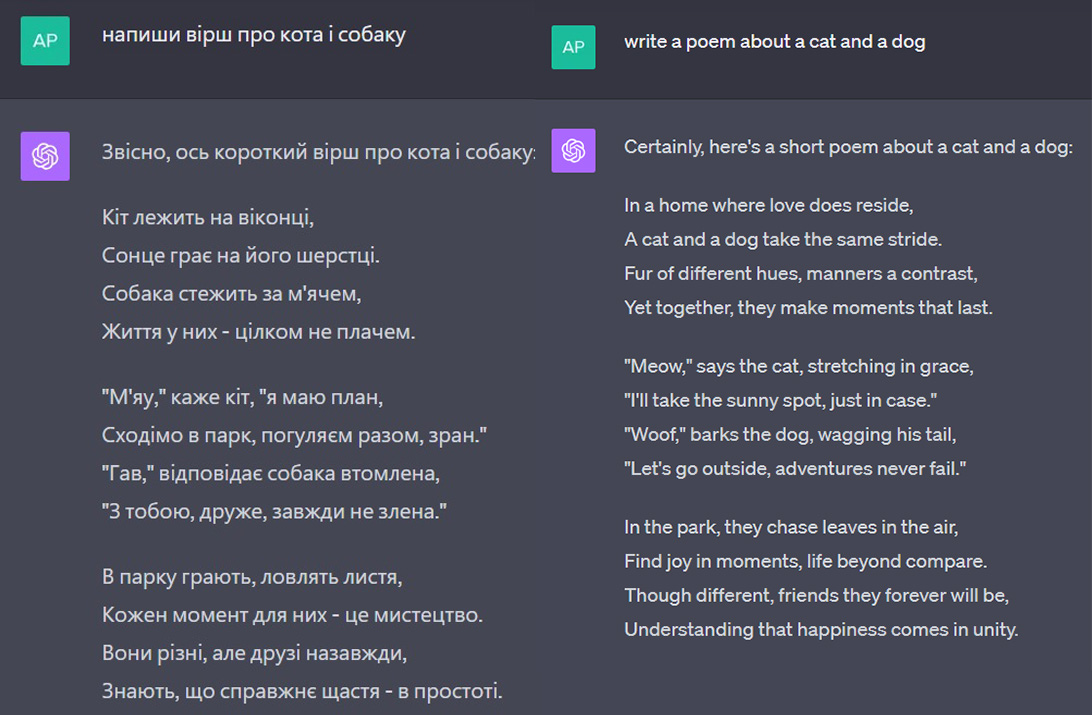
Если вы захотите получить стихотворение на украинском, творение искусственного интеллекта вряд ли вам понравится.
Ключ к пониманию этой проблемы – комбинация токенов. Если один токен представляет одно слово, как в случае с английским, то нейросеть может легко найти зависимости между этими словами, соединив их в рифмуемое произведение.
Когда же на одну букву уходит сразу несколько токенов, для нейросети найти эту связь между словами значительно труднее. Именно поэтому ChatGPT намного дольше и менее качественно генерирует тексты на украинском (причем не только стихи, но и обычные).
Правильно формулируйте задачи, то есть качественно прописывайте промпты – текстовые подсказки для нейросети, по которым вы направляете искусственный интеллект бродить по вашим задачам.
Благодаря своему интеллекту, а также широкому спектру разнообразных возможностей восприятия мира мы привыкли понимать друг друга с полуслова. В своем общении люди научились додумывать друг за друга и сразу понимать, что хочет сказать собеседник.
Такая коммуникация привычна для нас, но не для нейросетей. Им важно ставить четкие задачи, со всеми подробностями, о которых во время разговора с другими людьми мы даже не задумываемся.
Будет ли ChatGPT лучше работать с украинским
В ходе тренировки каждая нейросеть изучает множество данных. Ей показывают большое количество текстов, в которых AI ищет взаимозависимости.
Когда у AI-инструмента уже есть определенная база, ему показывают новые данные (Evaluation Dataset), которые он не видел раньше, чтобы проверить, насколько хорошо он понимает и генерирует подобные фразы.
Этот принцип похож на то, как учатся люди: сначала мы учим некоторые правила, а после решаем задачи для закрепления материала.
Летом один из пользователей Twitter рассказал, что OpenAI взял его украинскую базу данных именно для выполнения такой проверки. Теперь в будущем во время внутренних проверок точности работы ChatGPT или других AI-инструментов компании украинский язык будет иметь большее влияние на этот показатель.
Значит ли это, что уже скоро чат-бот будет классно работать на украинском? Нет.
Однако постепенное развитие архитектуры нейросетей должно привести нас в будущее, в котором AI-инструменты будут работать с разными языками гораздо лучше, чем сейчас.
Речь идет не только об улучшении ChatGPT или других инструментов. Это важный вызов, стоящий перед AI-сообществом на годы вперед: сделать AI универсальным для как можно большего числа людей.




Вы нашли ошибку или неточность?
Оставьте отзыв для редакции. Мы учтем ваши замечания как можно скорее.








